

As discussed in Part 2 of this series, relational databases offer many advantages. In this post, we discuss best practices for setting up your policy database to be as robust and effective as possible.
Relational databases have been around for years, and while the programs have become more sophisticated and also easier to use, the basic database theory remains the same.
First, let’s get a little geeky and talk normalization. To up the geek factor even more, consider what Albert Einstein said: “Make everything as simple as possible and no simpler.” When it comes to building any relational database — including a policy database — this is excellent advice.
Normalization is the process of organizing data to reduce redundancy by breaking it down into its simplest form with the minimum repeating parts. Why is repeating data a problem? Repeating data wastes space, leads to data inconsistencies, and makes the data difficult to maintain. For example, changing a carrier name should happen one time, not once for each policy the carrier issued.
How do we apply normalization principles to policy data effectively? Look for repeating values and ask yourself – how does this data change? Does it change by carrier, policy, year, named insured, or corporate history?
Consider a few basic fields:
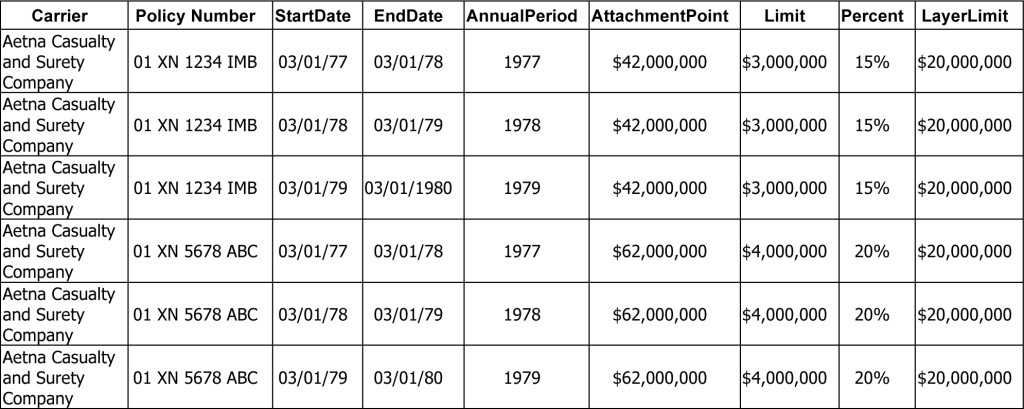
A normalized policy database would have a table to hold all of the carrier names, one for the policies, one for the dates and one for the limits. Each would relate to the other using ID fields (known as “Primary Keys” to the geeky crowd).
The above two policies normalized would look something like this …
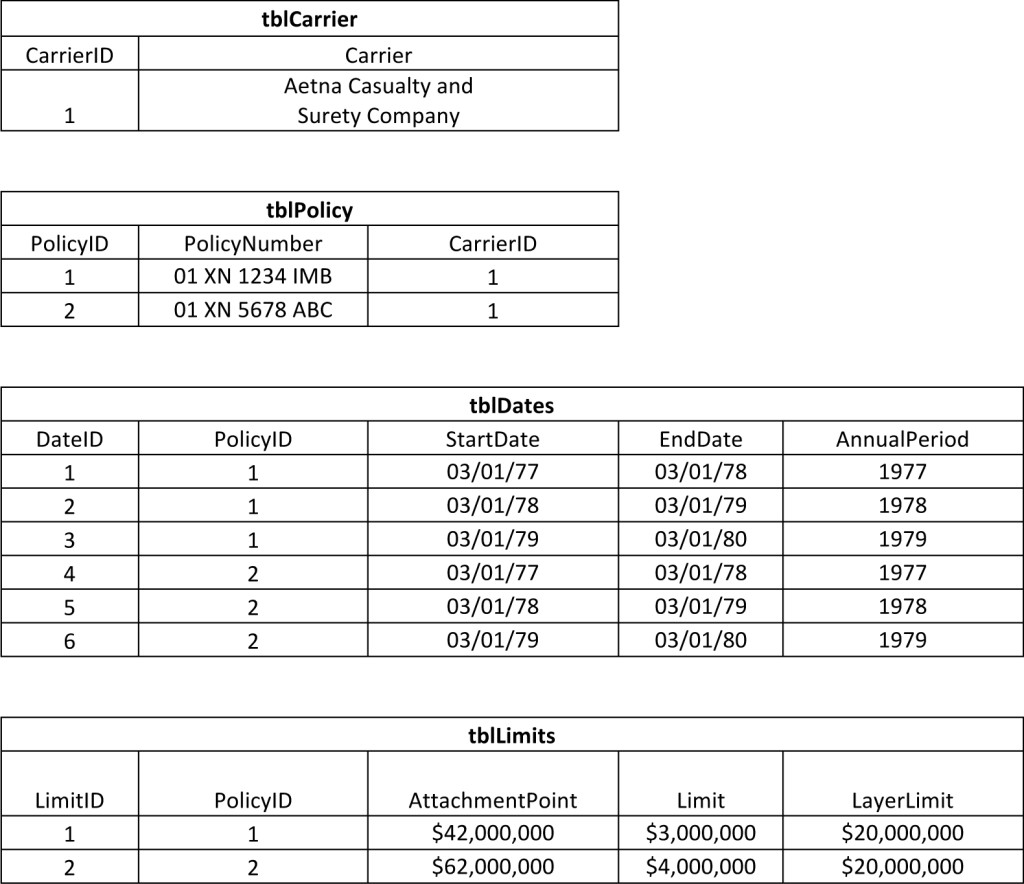
You might think the data looks much more complex after normalization — and would certainly disappoint Einstein. But actually, it’s simple when it comes to maintenance of the data and allows for tremendous flexibility in reporting and calculations.
The date table, tblDate, contains one record for each annual year of the policy. In that format, a policy can be reported later in three rows, each with one annual period, or collapsed into one period with the first start and last end date. Further, tblLimits could add a limit type field so that each policy can be related to multiple limit types such as property damage, bodily injury, advertising, etc.
The same exercise can be used for storing policy provisions, which vary by policy and sometimes by policy by date. You could design a policy language or provision table to “relate” back to the policy table using PolicyID or to the Date table using DateID (depending, in part, on your insurance program and how often provisions change by date versus changing by policy). Einstein’s rule should apply for each table created – the value in the rows of a table should all vary by the same basic subject matter.
The process could also be applied to policy language. Insurers often used the same preprinted forms for years. For example, the definition of Ultimate Net Loss doesn’t always vary between policies. Likewise, the same definition might be relevant to defense costs and other policy provisions. Instead of storing a new copy of the clause for each provision, a normalized design allows you to store it once, but associate it with as many policies and provisions as you need.
It is through these inter-policy connections and the elimination of duplicate data that the relational database structure becomes a powerful tool for managing and analyzing policy data. Our next postwill focus on how relational database technology can help you manage the status and value of your complicated London Market coverage.
What are your thoughts on normalization as it applies to policy data? Have you seen how reducing redundancy results in a more effective database?
Never miss a post. Get Risky Business tips and insights delivered right to your inbox.